问题定义

数据定义如下:
data = {'Size': [{'name': 'S', 'value': '0'}, {'name': 'M', 'value': '1'}, {'name': 'L', 'value': '2'},
{'name': 'XL', 'value': '3'}, {'name': '2XL', 'value': '4'}],
'Color': [{'name': 'Blacks', 'value': '5'}, {'name': 'Blues', 'value': '6'}, {'name': 'Grays', 'value': '7'},
{'name': 'Purples', 'value': '8'}, {'name': 'Whites', 'value': '9'}],
'Shade': [{'name': 'Ebony', 'value': '10'}, {'name': 'Light Steel', 'value': '11'},
{'name': 'Navy Heather', 'value': '12'}, {'name': 'Slate Heather', 'value': '13'},
{'name': 'Violet Splendor Heather', 'value': '14'}, {'name': 'White', 'value': '15'}]}
解决思路
pandas的dataframe具有merge语法,意思是数据的关联
如果我们想让两个dataframe的每个行都可以merge对应起来。可以用一个技巧,首先给每个dataframe增加一个key=1的常量列,这个数字1是任何一样的值都行。然后再用pd.merge做关联。关联的key就是这个常量值。
那么merge后,就实现了所有行的一对一合并的效果,其实就是笛卡尔积。
代码实现
data = {'Size': [{'name': 'S', 'value': '0'}, {'name': 'M', 'value': '1'}, {'name': 'L', 'value': '2'},
{'name': 'XL', 'value': '3'}, {'name': '2XL', 'value': '4'}],
'Color': [{'name': 'Blacks', 'value': '5'}, {'name': 'Blues', 'value': '6'}, {'name': 'Grays', 'value': '7'},
{'name': 'Purples', 'value': '8'}, {'name': 'Whites', 'value': '9'}],
'Shade': [{'name': 'Ebony', 'value': '10'}, {'name': 'Light Steel', 'value': '11'},
{'name': 'Navy Heather', 'value': '12'}, {'name': 'Slate Heather', 'value': '13'},
{'name': 'Violet Splendor Heather', 'value': '14'}, {'name': 'White', 'value': '15'}]}
import pandas as pd
df_list = []
for key in data.keys():
df = pd.DataFrame(data[key])
df["key"] = 1
# print(df)
df_list.append(df)
df_all = df_list[0]
for df in df_list[1:]:
df_all = pd.merge(df_all, df, left_on="key", right_on="key")
print(df_all)
df_all.to_csv("合并后的结果.csv", encoding="utf8")
效果展示
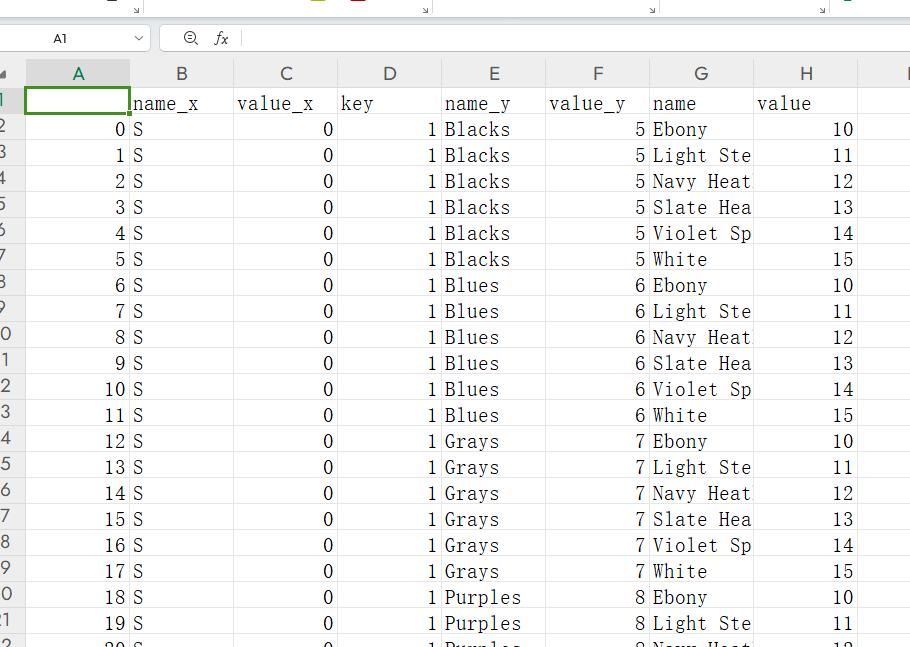
实现了笛卡尔积的效果。