例如语法:
df.loc[df["销量"].str.contains("万件"), "销量值"] = \
df.loc[df["销量"].str.contains("万件"), "销量"].str.extract(r'热销(\d+\.\d+)万件\(近\d+小时\)')[0].astype(float) * 10000 需要加;
但是语法
df["销量值"] = df["销量"].str.extract(r'热销(\d+)件\(近\d+小时\)')这个不需要加
简单总结
df["销量值"]如果作为等式的左侧,可以在等号右侧接收一个dataframe,所以右侧不用加[0]df.loc[df["销量"].str.contains("万件"), "销量值"]如果作为等式的左侧,那么右侧得提供一个Series,所以得加[0]
几个类型的区别
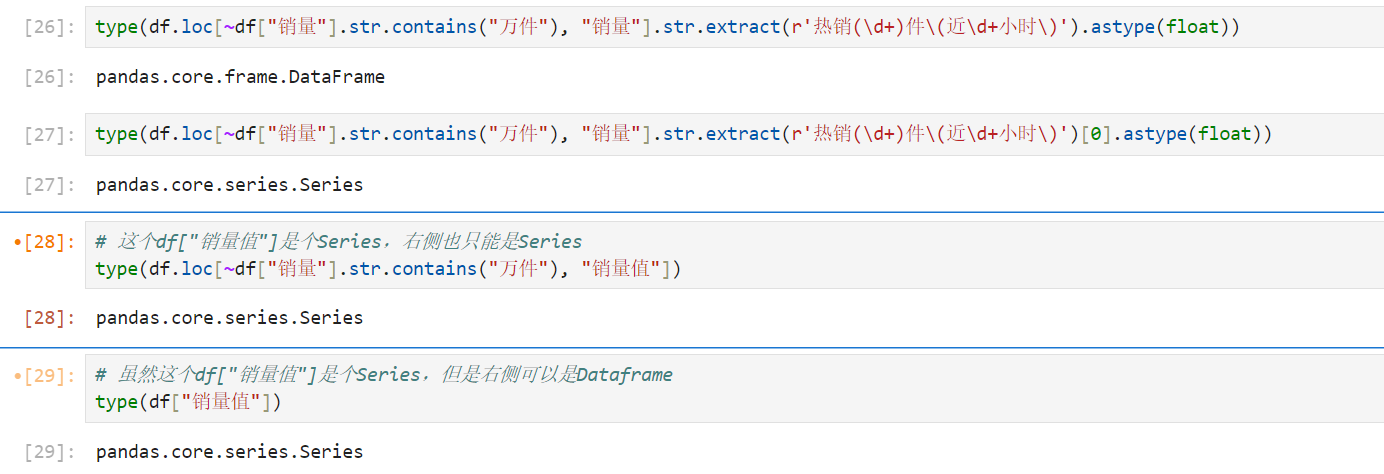
解释
pandas 的 str.extract() 返回的结果是一个包含提取字段的 DataFrame,因此是否需要加 [0] 取决于提取结果的结构和期望的输出格式。
情况 1:需要加 [0]
当你使用正则表达式匹配多个组时,即使你只提取了一个字段,str.extract() 返回的是一个 DataFrame,列的数量等于捕获的组数。在这种情况下,如果你只关心某一列的值,你需要用 [0] 来访问 DataFrame 中的第一列。
例如:
df["销量"].str.extract(r'热销(\d+\.\d+)万件\(近\d+小时\)')此时返回的是一个 DataFrame,只有一列,该列包含提取的浮点数。所以你需要通过 [0] 来提取这一列的数据,并将其转换为 Series:
df["销量值"] = df["销量"].str.extract(r'热销(\d+\.\d+)万件\(近\d+小时\)')[0]情况 2:不需要加 [0]
如果你在正则表达式中只捕获了一个字段,并且你使用 str.extract() 提取的字段已经是你想要的结果,并且你希望以 DataFrame 形式处理或没有进一步访问某一列的需求时,不需要加 [0]。
例如:
df["销量值"] = df["销量"].str.extract(r'热销(\d+)件\(近\d+小时\)')这个正则表达式只匹配了一个整数((\d+)),返回的 DataFrame 也只包含一列。如果你直接想将该列赋给新的列 销量值,那么就不需要 [0],因为它已经是你需要的内容。
总结
- 需要
[0]:当str.extract()返回多个捕获组或你希望将结果从 DataFrame 转换为 Series 时。 - 不需要
[0]:当str.extract()只匹配一个字段并且你不需要对 DataFrame 的列进行额外操作时。
所以,[0] 是用来从提取的 DataFrame 中选取第一列的,而在你只捕获单一字段且没有特殊操作的情况下则不需要。