方法1
series是一个字典
用字典的方式,新增字段值;
这个字典中,将包含旧的值,以及新的值;
def sizes(s):
s['size_kb'] = locale.format("%.1f", s['size'] / 1024.0, grouping=True) + ' KB'
s['size_mb'] = locale.format("%.1f", s['size'] / 1024.0 ** 2, grouping=True) + ' MB'
s['size_gb'] = locale.format("%.1f", s['size'] / 1024.0 ** 3, grouping=True) + ' GB'
return s
df_test = df_test.append(rows_list)
df_test = df_test.apply(sizes, axis=1)
方法2:
拆解成三个字段列
def sizes(s):
return locale.format("%.1f", s / 1024.0, grouping=True) + ' KB', \
locale.format("%.1f", s / 1024.0 ** 2, grouping=True) + ' MB', \
locale.format("%.1f", s / 1024.0 ** 3, grouping=True) + ' GB'
df_test['size_kb'], df_test['size_mb'], df_test['size_gb'] = zip(*df_test['size'].apply(sizes))
方法3:
import pandas as pd
df_test = pd.DataFrame([
{'dir': '/Users/uname1', 'size': 994933},
{'dir': '/Users/uname2', 'size': 109338711},
])
def sizes(s):
a = locale.format_string("%.1f", s['size'] / 1024.0, grouping=True) + ' KB'
b = locale.format_string("%.1f", s['size'] / 1024.0 ** 2, grouping=True) + ' MB'
c = locale.format_string("%.1f", s['size'] / 1024.0 ** 3, grouping=True) + ' GB'
return a, b, c
df_test[['size_kb', 'size_mb', 'size_gb']] = df_test.apply(sizes, axis=1, result_type="expand")
expand关键字的作用:
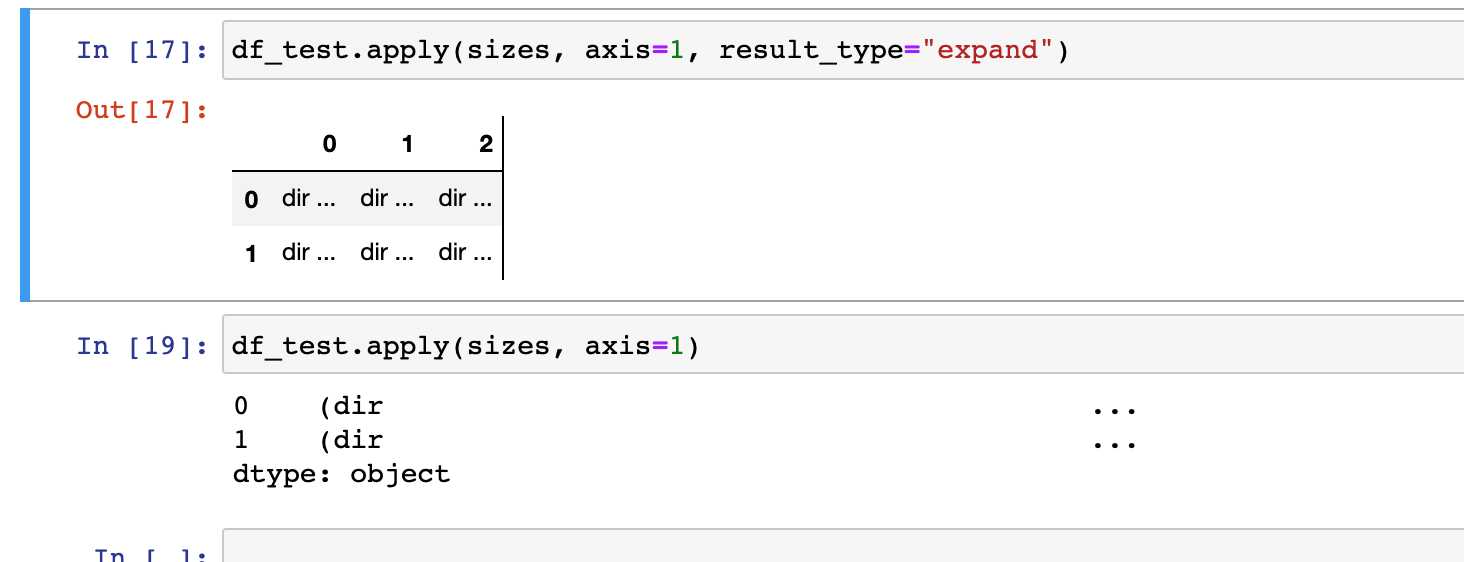
方法4:
def sizes(s):
val_kb = locale.format("%.1f", s['size'] / 1024.0, grouping=True) + ' KB'
val_mb = locale.format("%.1f", s['size'] / 1024.0 ** 2, grouping=True) + ' MB'
val_gb = locale.format("%.1f", s['size'] / 1024.0 ** 3, grouping=True) + ' GB'
return pd.Series([val_kb,val_mb,val_gb],index=['size_kb','size_mb','size_gb'])
df[['size_kb','size_mb','size_gb']] = df.apply(lambda x: sizes(x) , axis=1)
综合
import pandas as pd
dat = [ [i, 10*i] for i in range(1000)]
df = pd.DataFrame(dat, columns = ["a","b"])
def add_and_sub(row):
add = row["a"] + row["b"]
sub = row["a"] - row["b"]
return add, sub
df[["add", "sub"]] = df.apply(add_and_sub, axis=1, result_type="expand")
# versus
df["add"], df["sub"] = zip(*df.apply(add_and_sub, axis=1))
来源:
https://stackoverflow.com/questions/23586510/return-multiple-columns-from-pandas-apply