本文的代码,从https://github.com/cleverdeng/pinyin.py升级得来,针对原文的代码,做了以下升级:
1、可以传入参数firstcode:如果为true,只取汉子的第一个拼音字母;如果为false,则会输出全部拼音; 2、修复:如果为英文字母,则直接输出; 3、修复:如果分隔符为空字符串,仍然能正常输出; 4、升级:可以指定词典的文件路径
代码很简单,直接读取了一个词典(字符和英文的映射),然后挨个替换中文中的拼音即可;
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
原版代码:https://github.com/cleverdeng/pinyin.py
新增功能:
1、可以传入参数firstcode:如果为true,只取汉子的第一个拼音字母;如果为false,则会输出全部拼音;
2、修复:如果为英文字母,则直接输出;
3、修复:如果分隔符为空字符串,仍然能正常输出;
4、升级:可以指定词典的文件路径
"""
__version__ = '0.9'
__all__ = ["PinYin"]
import os.path
class PinYin(object):
def __init__(self):
self.word_dict = {}
def load_word(self, dict_file):
self.dict_file = dict_file
if not os.path.exists(self.dict_file):
raise IOError("NotFoundFile")
with file(self.dict_file) as f_obj:
for f_line in f_obj.readlines():
try:
line = f_line.split(' ')
self.word_dict[line[0]] = line[1]
except:
line = f_line.split(' ')
self.word_dict[line[0]] = line[1]
def hanzi2pinyin(self, string="", firstcode=False):
result = []
if not isinstance(string, unicode):
string = string.decode("utf-8")
for char in string:
key = '%X' % ord(char)
value = self.word_dict.get(key, char)
outpinyin = str(value).split()[0][:-1].lower()
if not outpinyin:
outpinyin = char
if firstcode:
result.append(outpinyin[0])
else:
result.append(outpinyin)
return result
def hanzi2pinyin_split(self, string="", split="", firstcode=False):
"""提取中文的拼音
@param string:要提取的中文
@param split:分隔符
@param firstcode: 提取的是全拼还是首字母?如果为true表示提取首字母,默认为False提取全拼
"""
result = self.hanzi2pinyin(string=string, firstcode=firstcode)
return split.join(result)
if __name__ == "__main__":
test = PinYin()
test.load_word('word.data')
string = "Java程序性能优化-让你的Java程序更快更稳定"
print "in: %s" % string
print "out: %s" % str(test.hanzi2pinyin(string=string))
print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=True)
print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=False)
实例中main函数的代码输出结果

代码使用方法:
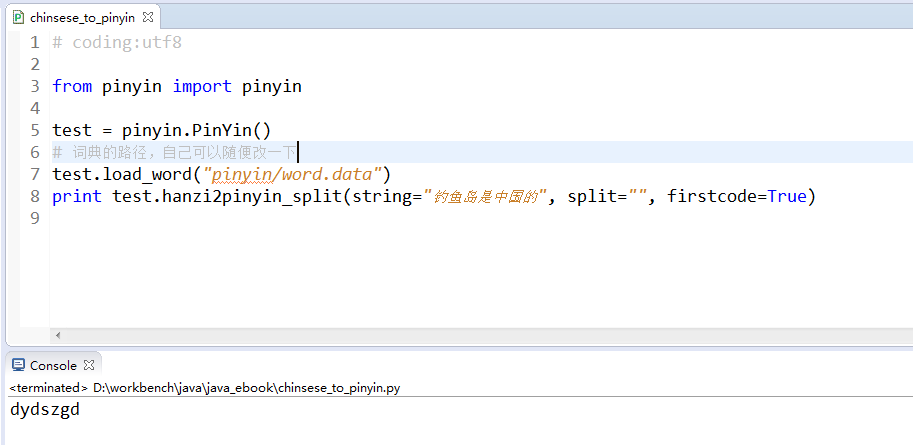
如果需要其他的提取,可以修改一下代码实现;
代码(包含词典)打包下载: